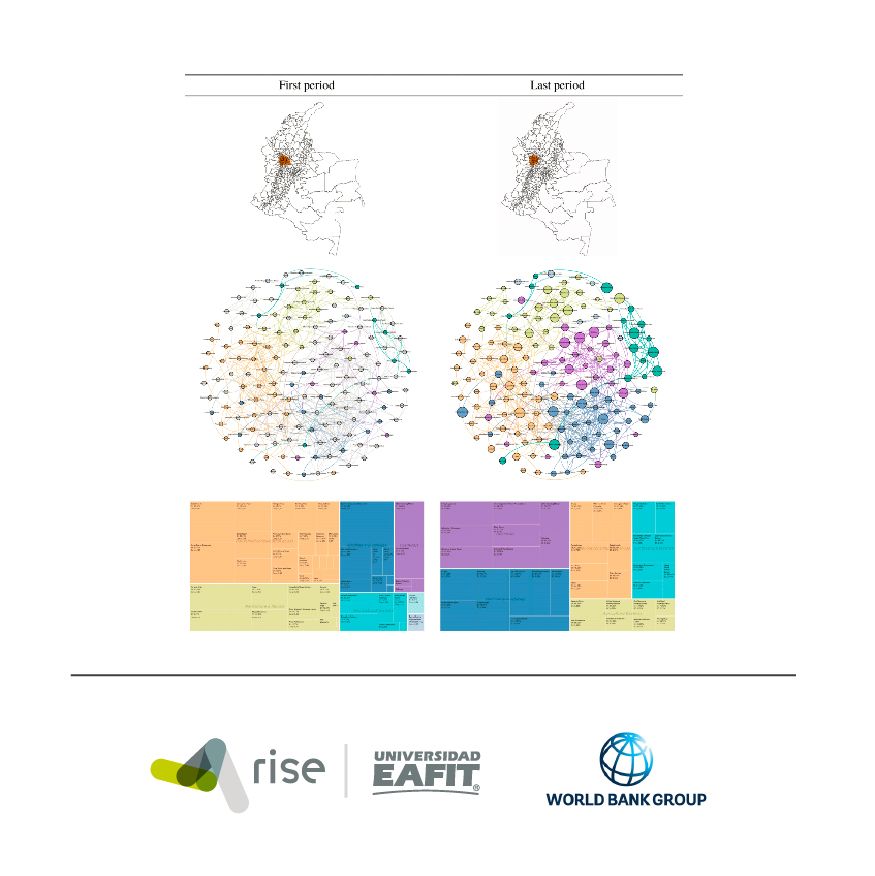
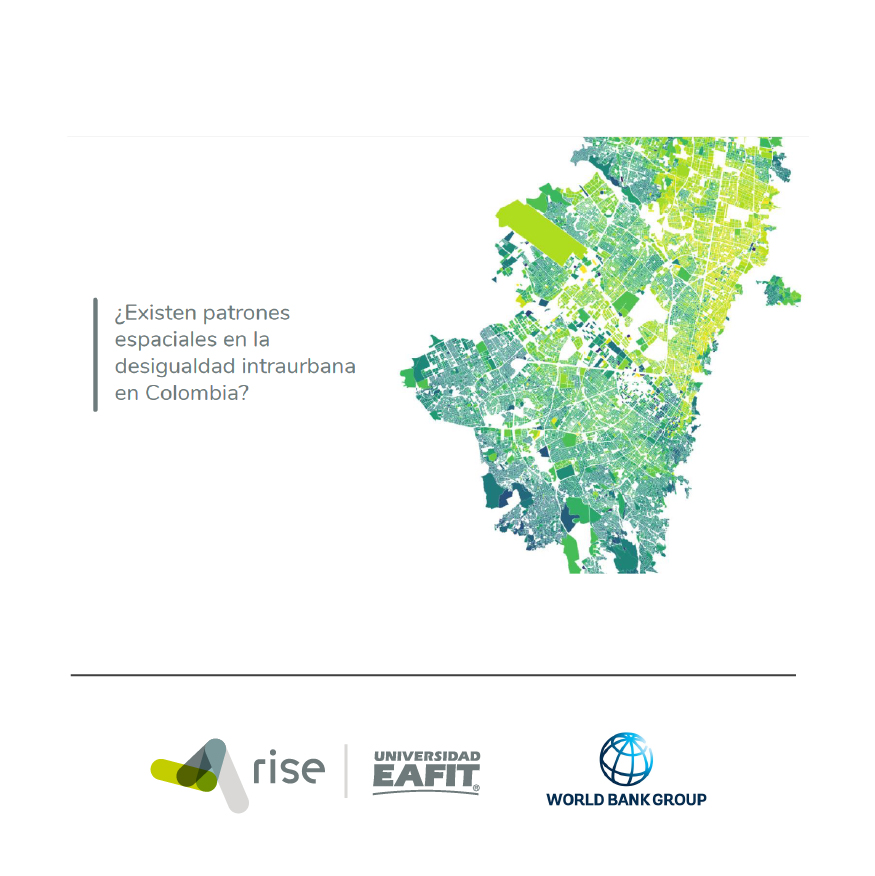
Artículos de revista
|
2021
|
Gómez, Jairo A; Guan, ChengHe ; Tripathy, Pratyush ; Duque, Juan C; Passos, Santiago ; Keith, Michael ; Liu, Jialin Analyzing the Spatiotemporal Uncertainty in Urbanization Predictions Artículo de revista Remote Sensing, 13 (3), pp. 28, 2021, ISSN: 2072-4292. Resumen | Enlaces | BibTeX | Etiquetas: Aprendizaje de máquina, Crecimiento de ciudades @article{rs13030512,
title = {Analyzing the Spatiotemporal Uncertainty in Urbanization Predictions},
author = {Gómez, Jairo A. and Guan, ChengHe and Tripathy, Pratyush and Duque, Juan C. and Passos, Santiago and Keith, Michael and Liu, Jialin},
editor = {MDPI},
url = {https://doi.org/10.3390/rs13030512},
doi = {10.3390/rs13030512},
issn = {2072-4292},
year = {2021},
date = {2021-02-01},
journal = {Remote Sensing},
volume = {13},
number = {3},
pages = {28},
abstract = {With the availability of computational resources, geographical information systems, and remote sensing data, urban growth modeling has become a viable tool for predicting urbanization of cities and towns, regions, and nations around the world. This information allows policy makers, urban planners, environmental and civil organizations to make investments, design infrastructure, extend public utility networks, plan housing solutions, and mitigate adverse environmental impacts. Despite its importance, urban growth models often discard the spatiotemporal uncertainties in their prediction estimates. In this paper, we analyzed the uncertainty in the urban land predictions by comparing the outcomes of two different growth models, one based on a widely applied cellular automata model known as the SLEUTH CA and the other one based on a previously published machine learning framework. We selected these two models because they are complementary, the first is based on human knowledge and pre-defined and understandable policies while the second is more data-driven and might be less influenced by any a priori knowledge or bias. To test our methodology, we chose the cities of Jiaxing and Lishui in China because they are representative of new town planning policies and have different characteristics in terms of land extension, geographical conditions, growth rates, and economic drivers. We focused on the spatiotemporal uncertainty, understood as the inherent doubt in the predictions of where and when will a piece of land become urban, using the concepts of certainty area in space and certainty area in time. The proposed analyses in this paper aim to contribute to better urban planning exercises, and they can be extended to other cities worldwide.},
keywords = {Aprendizaje de máquina, Crecimiento de ciudades},
pubstate = {published},
tppubtype = {article}
}
With the availability of computational resources, geographical information systems, and remote sensing data, urban growth modeling has become a viable tool for predicting urbanization of cities and towns, regions, and nations around the world. This information allows policy makers, urban planners, environmental and civil organizations to make investments, design infrastructure, extend public utility networks, plan housing solutions, and mitigate adverse environmental impacts. Despite its importance, urban growth models often discard the spatiotemporal uncertainties in their prediction estimates. In this paper, we analyzed the uncertainty in the urban land predictions by comparing the outcomes of two different growth models, one based on a widely applied cellular automata model known as the SLEUTH CA and the other one based on a previously published machine learning framework. We selected these two models because they are complementary, the first is based on human knowledge and pre-defined and understandable policies while the second is more data-driven and might be less influenced by any a priori knowledge or bias. To test our methodology, we chose the cities of Jiaxing and Lishui in China because they are representative of new town planning policies and have different characteristics in terms of land extension, geographical conditions, growth rates, and economic drivers. We focused on the spatiotemporal uncertainty, understood as the inherent doubt in the predictions of where and when will a piece of land become urban, using the concepts of certainty area in space and certainty area in time. The proposed analyses in this paper aim to contribute to better urban planning exercises, and they can be extended to other cities worldwide. |
2020
|
Gómez, Jairo A; Patiño, Jorge E; Duque, Juan C; Passos, Santiago Spatiotemporal Modeling of Urban Growth Using Machine Learning Artículo de revista Remote Sensing, 12(1) (109), pp. 1-41, 2020, ISSN: 2072-4292. Resumen | Enlaces | BibTeX | Etiquetas: Aprendizaje de máquina, Crecimiento de ciudades, imágenes satelitales @article{gomez2020spatiotemporal,
title = {Spatiotemporal Modeling of Urban Growth Using Machine Learning},
author = {Gómez, Jairo A. and Patiño, Jorge E. and Duque, Juan C. and Passos, Santiago },
url = {https://doi.org/10.3390/rs12010109},
doi = {10.3390/rs12010109},
issn = {2072-4292},
year = {2020},
date = {2020-01-01},
journal = {Remote Sensing},
volume = {12(1)},
number = {109},
pages = {1-41},
abstract = {This paper presents a general framework for modeling the growth of three important variables for cities: population distribution, binary urban footprint, and urban footprint in color. The framework models the population distribution as a spatiotemporal regression problem using machine learning, and it obtains the binary urban footprint from the population distribution through a binary classifier plus a temporal correction for existing urban regions. The framework estimates the urban footprint in color from its previous value, as well as from past and current values of the binary urban footprint using a semantic inpainting algorithm. By combining this framework with free data from the Landsat archive and the Global Human Settlement Layer framework, interested users can get approximate growth predictions of any city in the world. These predictions can be improved with the inclusion in the framework of additional spatially distributed input variables over time subject to availability. Unlike widely used growth models based on cellular automata, there are two main advantages of using the proposed machine learning-based framework. Firstly, it does not require to define rules a priori because the model learns the dynamics of growth directly from the historical data. Secondly, it is very easy to train new machine learning models using different explanatory input variables to assess their impact. As a proof of concept, we tested the framework in Valledupar and Rionegro, two Latin American cities located in Colombia with different geomorphological characteristics, and found that the model predictions were in close agreement with the ground-truth based on performance metrics, such as the root-mean-square error, zero-mean normalized cross-correlation, Pearson’s correlation coefficient for continuous variables, and a few others for discrete variables such as the intersection over union, accuracy, and the f1 metric. In summary, our framework for modeling urban growth is flexible, allows sensitivity analyses, and can help policymakers worldwide to assess different what-if scenarios during the planning cycle of sustainable and resilient cities.},
keywords = {Aprendizaje de máquina, Crecimiento de ciudades, imágenes satelitales},
pubstate = {published},
tppubtype = {article}
}
This paper presents a general framework for modeling the growth of three important variables for cities: population distribution, binary urban footprint, and urban footprint in color. The framework models the population distribution as a spatiotemporal regression problem using machine learning, and it obtains the binary urban footprint from the population distribution through a binary classifier plus a temporal correction for existing urban regions. The framework estimates the urban footprint in color from its previous value, as well as from past and current values of the binary urban footprint using a semantic inpainting algorithm. By combining this framework with free data from the Landsat archive and the Global Human Settlement Layer framework, interested users can get approximate growth predictions of any city in the world. These predictions can be improved with the inclusion in the framework of additional spatially distributed input variables over time subject to availability. Unlike widely used growth models based on cellular automata, there are two main advantages of using the proposed machine learning-based framework. Firstly, it does not require to define rules a priori because the model learns the dynamics of growth directly from the historical data. Secondly, it is very easy to train new machine learning models using different explanatory input variables to assess their impact. As a proof of concept, we tested the framework in Valledupar and Rionegro, two Latin American cities located in Colombia with different geomorphological characteristics, and found that the model predictions were in close agreement with the ground-truth based on performance metrics, such as the root-mean-square error, zero-mean normalized cross-correlation, Pearson’s correlation coefficient for continuous variables, and a few others for discrete variables such as the intersection over union, accuracy, and the f1 metric. In summary, our framework for modeling urban growth is flexible, allows sensitivity analyses, and can help policymakers worldwide to assess different what-if scenarios during the planning cycle of sustainable and resilient cities. |
2017
|
Duque, Juan C; Patino, Jorge E; Betancourt, Alejandro Exploring the potential of machine learning for automatic slum identification from VHR imagery Artículo de revista Remote Sensing, 9(9) (895), pp. 1-23, 2017, ISSN: 2072-4292. Resumen | Enlaces | BibTeX | Etiquetas: Aprendizaje de máquina, imágenes satelitales, pobreza, Sostenibilidad de ciudades @article{duque2017exploring,
title = {Exploring the potential of machine learning for automatic slum identification from VHR imagery},
author = {Duque, Juan C. and Patino, Jorge E. and Betancourt, Alejandro},
url = {https://doi.org/10.3390/rs9090895},
doi = {10.3390/rs9090895},
issn = {2072-4292},
year = {2017},
date = {2017-08-30},
journal = {Remote Sensing},
volume = {9(9)},
number = {895},
pages = {1-23},
abstract = {Slum identification in urban settlements is a crucial step in the process of formulation of pro-poor policies. However, the use of conventional methods for slum detection such as field surveys can be time-consuming and costly. This paper explores the possibility of implementing a low-cost standardized method for slum detection. We use spectral, texture and structural features extracted from very high spatial resolution imagery as input data and evaluate the capability of three machine learning algorithms (Logistic Regression, Support Vector Machine and Random Forest) to classify urban areas as slum or no-slum. Using data from Buenos Aires (Argentina), Medellin (Colombia) and Recife (Brazil), we found that Support Vector Machine with radial basis kernel delivers the best performance (with F2-scores over 0.81). We also found that singularities within cities preclude the use of a unified classification model.},
keywords = {Aprendizaje de máquina, imágenes satelitales, pobreza, Sostenibilidad de ciudades},
pubstate = {published},
tppubtype = {article}
}
Slum identification in urban settlements is a crucial step in the process of formulation of pro-poor policies. However, the use of conventional methods for slum detection such as field surveys can be time-consuming and costly. This paper explores the possibility of implementing a low-cost standardized method for slum detection. We use spectral, texture and structural features extracted from very high spatial resolution imagery as input data and evaluate the capability of three machine learning algorithms (Logistic Regression, Support Vector Machine and Random Forest) to classify urban areas as slum or no-slum. Using data from Buenos Aires (Argentina), Medellin (Colombia) and Recife (Brazil), we found that Support Vector Machine with radial basis kernel delivers the best performance (with F2-scores over 0.81). We also found that singularities within cities preclude the use of a unified classification model. |
Arribas-Bel, Daniel ; Patino, Jorge E; Duque, Juan C Remote sensing-based measurement of Living Environment Deprivation: Improving classical approaches with machine learning Artículo de revista PloS one, 12 (4), pp. 1-25, 2017, ISSN: 1932-6203. Resumen | Enlaces | BibTeX | Etiquetas: Aprendizaje de máquina, pobreza, Sostenibilidad de ciudades @article{arribas2017remote,
title = {Remote sensing-based measurement of Living Environment Deprivation: Improving classical approaches with machine learning},
author = {Arribas-Bel, Daniel and Patino, Jorge E. and Duque, Juan C.},
url = {https://doi.org/10.1371/journal.pone.0176684},
doi = {10.1371/journal.pone.0176684},
issn = { 1932-6203},
year = {2017},
date = {2017-05-02},
journal = {PloS one},
volume = {12},
number = {4},
pages = {1-25},
abstract = {This paper provides evidence on the usefulness of very high spatial resolution (VHR) imagery in gathering socioeconomic information in urban settlements. We use land cover, spectral, structure and texture features extracted from a Google Earth image of Liverpool (UK) to evaluate their potential to predict Living Environment Deprivation at a small statistical area level. We also contribute to the methodological literature on the estimation of socioeconomic indices with remote-sensing data by introducing elements from modern machine learning. In addition to classical approaches such as Ordinary Least Squares (OLS) regression and a spatial lag model, we explore the potential of the Gradient Boost Regressor and Random Forests to improve predictive performance and accuracy. In addition to novel predicting methods, we also introduce tools for model interpretation and evaluation such as feature importance and partial dependence plots, or cross-validation. Our results show that Random Forest proved to be the best model with an R2 of around 0.54, followed by Gradient Boost Regressor with 0.5. Both the spatial lag model and the OLS fall behind with significantly lower performances of 0.43 and 0.3, respectively.},
keywords = {Aprendizaje de máquina, pobreza, Sostenibilidad de ciudades},
pubstate = {published},
tppubtype = {article}
}
This paper provides evidence on the usefulness of very high spatial resolution (VHR) imagery in gathering socioeconomic information in urban settlements. We use land cover, spectral, structure and texture features extracted from a Google Earth image of Liverpool (UK) to evaluate their potential to predict Living Environment Deprivation at a small statistical area level. We also contribute to the methodological literature on the estimation of socioeconomic indices with remote-sensing data by introducing elements from modern machine learning. In addition to classical approaches such as Ordinary Least Squares (OLS) regression and a spatial lag model, we explore the potential of the Gradient Boost Regressor and Random Forests to improve predictive performance and accuracy. In addition to novel predicting methods, we also introduce tools for model interpretation and evaluation such as feature importance and partial dependence plots, or cross-validation. Our results show that Random Forest proved to be the best model with an R2 of around 0.54, followed by Gradient Boost Regressor with 0.5. Both the spatial lag model and the OLS fall behind with significantly lower performances of 0.43 and 0.3, respectively. |