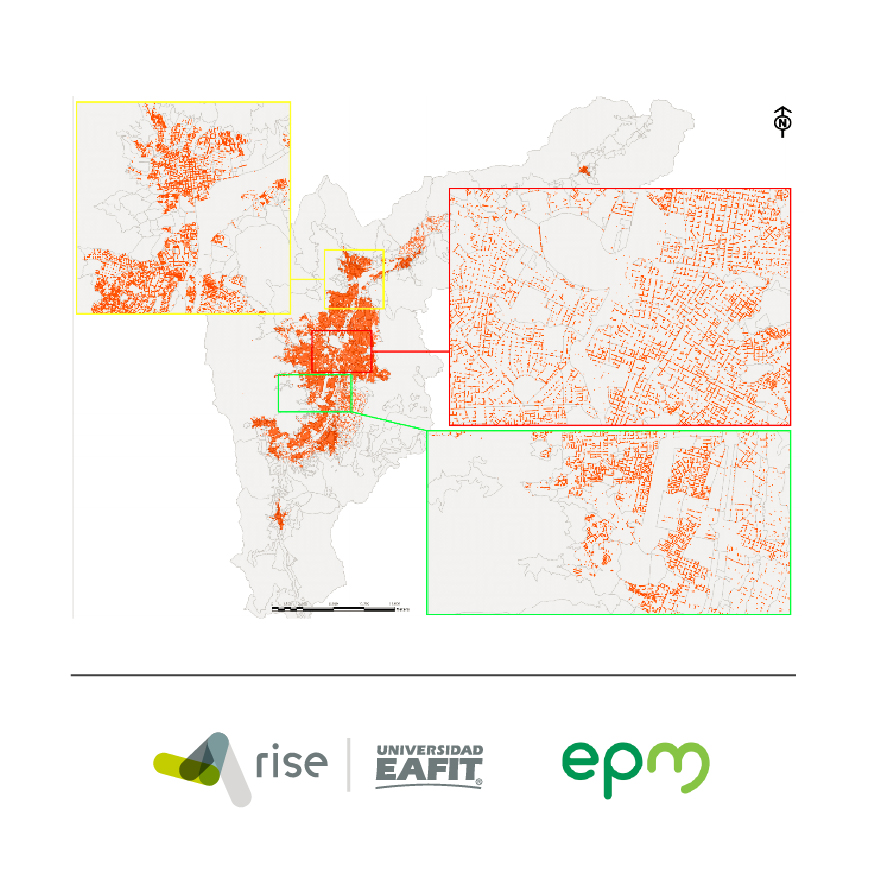
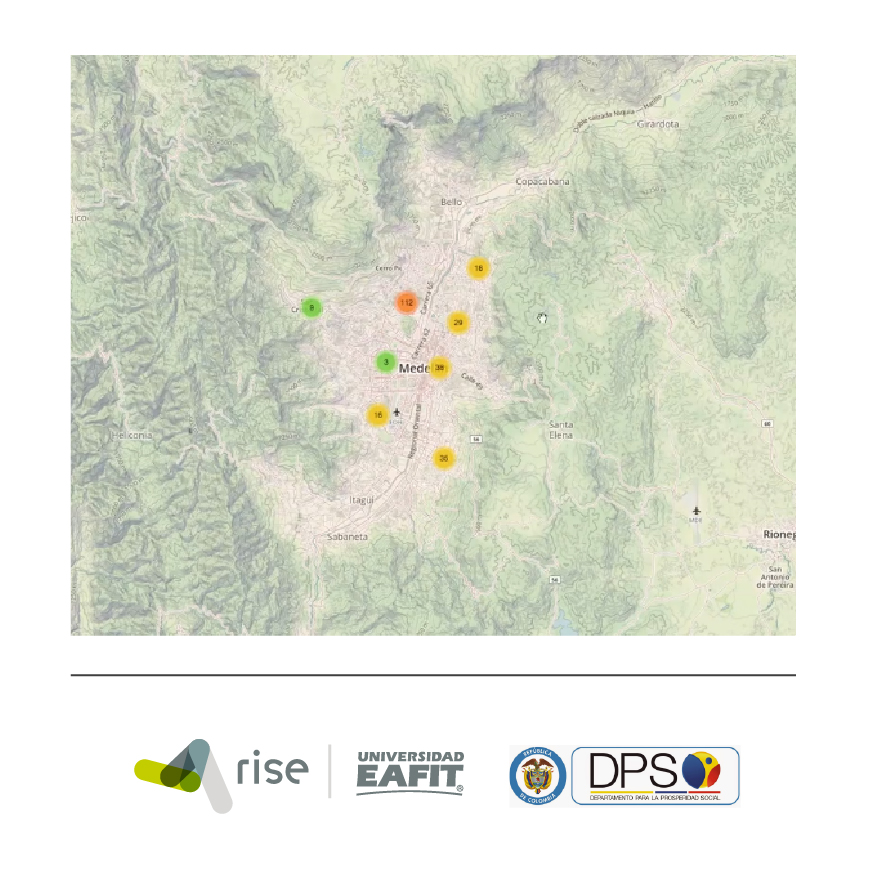
Duque, Juan C; Vélez-Gallego, Mario C; Echeverri, Laura C On the Performance of the Subtour Elimination Constraints Approach for the p-Regions Problem: A Computational Study Artículo de revista Geographical Analysis, 50 (1), pp. 32-52, 2018, ISSN: 1538-4632. Resumen | Enlaces | BibTeX | Etiquetas: Diseño de regiones @article{duque2018performance,
title = {On the Performance of the Subtour Elimination Constraints Approach for the p-Regions Problem: A Computational Study},
author = {Duque, Juan C. and Vélez-Gallego, Mario C. and Echeverri, Laura C.},
url = {https://doi.org/10.1111/gean.12132},
doi = {10.1111/gean.12132},
issn = {1538-4632},
year = {2018},
date = {2018-01-22},
journal = {Geographical Analysis},
volume = {50},
number = {1},
pages = {32-52},
abstract = {The p‐regions is a mixed integer programming (MIP) model for the exhaustive clustering of a set of n geographic areas into p spatially contiguous regions while minimizing measures of intraregional heterogeneity. This is an NP‐hard problem that requires a constant research of strategies to increase the size of instances that can be solved using exact optimization techniques. In this article, we explore the benefits of an iterative process that begins by solving the relaxed version of the p‐regions that removes the constraints that guarantee the spatial contiguity of the regions. Then, additional constraints are incorporated iteratively to solve spatial discontinuities in the regions. In particular we explore the relationship between the level of spatial autocorrelation of the aggregation variable and the benefits obtained from this iterative process. The results show that high levels of spatial autocorrelation reduce computational times because the spatial patterns tend to create spatially contiguous regions. However, we found that the greatest benefits are obtained in two situations: (1) when urn:x-wiley:00167363:media:gean12132:gean12132-math-0001; and (2) when the parameter p is close to the number of clusters in the spatial pattern of the aggregation variable.},
keywords = {Diseño de regiones},
pubstate = {published},
tppubtype = {article}
}
The p‐regions is a mixed integer programming (MIP) model for the exhaustive clustering of a set of n geographic areas into p spatially contiguous regions while minimizing measures of intraregional heterogeneity. This is an NP‐hard problem that requires a constant research of strategies to increase the size of instances that can be solved using exact optimization techniques. In this article, we explore the benefits of an iterative process that begins by solving the relaxed version of the p‐regions that removes the constraints that guarantee the spatial contiguity of the regions. Then, additional constraints are incorporated iteratively to solve spatial discontinuities in the regions. In particular we explore the relationship between the level of spatial autocorrelation of the aggregation variable and the benefits obtained from this iterative process. The results show that high levels of spatial autocorrelation reduce computational times because the spatial patterns tend to create spatially contiguous regions. However, we found that the greatest benefits are obtained in two situations: (1) when urn:x-wiley:00167363:media:gean12132:gean12132-math-0001; and (2) when the parameter p is close to the number of clusters in the spatial pattern of the aggregation variable. |
She, Bing ; Duque, Juan C; Ye, Xinyue The network-max-P-regions model Artículo de revista International Journal of Geographical Information Science, 31 (5), pp. 962-981, 2016, ISSN: 1362-3087. Resumen | Enlaces | BibTeX | Etiquetas: Análisis espacial, Diseño de regiones @article{she2017network,
title = {The network-max-P-regions model},
author = {She, Bing and Duque, Juan C. and Ye, Xinyue},
url = {https://doi.org/10.1080/13658816.2016.1252987},
doi = {10.1080/13658816.2016.1252987},
issn = {1362-3087},
year = {2016},
date = {2016-11-04},
journal = {International Journal of Geographical Information Science},
volume = {31},
number = {5},
pages = {962-981},
abstract = {This paper introduces a new p-regions model called the Network-Max-P-Regions (NMPR) model. The NMPR is a regionalization model that aims to aggregate n areas into the maximum number of regions (max-p) that satisfy a threshold constraint and to minimize the heterogeneity while taking into account the influence of a street network. The exact formulation of the NMPR is presented, and a heuristic solution is proposed to effectively compute the near-optimized partitions in several simulation datasets and a case study in Wuhan, China.},
keywords = {Análisis espacial, Diseño de regiones},
pubstate = {published},
tppubtype = {article}
}
This paper introduces a new p-regions model called the Network-Max-P-Regions (NMPR) model. The NMPR is a regionalization model that aims to aggregate n areas into the maximum number of regions (max-p) that satisfy a threshold constraint and to minimize the heterogeneity while taking into account the influence of a street network. The exact formulation of the NMPR is presented, and a heuristic solution is proposed to effectively compute the near-optimized partitions in several simulation datasets and a case study in Wuhan, China. |